CODESYS String Libraries
Einleitung
Die Bibliotheken im Package CODESYS String Libraries können für die Verarbeitung von Zeichenketten, die UTF-8 kodiert sind, eingesetzt werden. Grundlage ist die Schnittstelle IString aus der Bibliothek String Segments. Mithilfe dieser Schnittstelle können die Zeichenketten per Referenz an die jeweiligen Funktionen übergeben werden. Zur Erstellung einer IString-Instanz gibt es beispielsweise den Funktionsbaustein GSB.UTF8String aus der Bibliothek Generic String Base.
| Basisfunktionen für | |
| Effiziente Verwaltung von UTF-8 kodierten String-Segmenten | |
| Umwandlung von Zeichenketten unterschiedlicher Kodierung von/nach UTF-8 | |
| Funktionen für die Verarbeitung von UTF-8 kodierten Zeichenketten nach dem Vorbild der herkömmlichen Standardbibliothek | |
| Funktionen für die Verarbeitung von Unicoce-Zeichenkategorien | |
| Basisfunktion für die Handhabung von UTF-16 kodierten Speicherbereichen | |
| Basisfunktion für die Handhabung von UTF-8 kodierten Speicherbereichen | |
| Bausteine zur Verarbeitung von UTF-8-kodierten Zeichenketten, die ihren Speicherplatz statisch über |
Vorteile der neuen String-Bibliotheken
Wichtig
Die neuen String-Bibliotheken ersetzen nicht die altbekannten String-Funktionen der Bibliotheken Standard und Standard64. Wir empfehlen dennoch, für neue Projekte die neuen String-Bibliotheken zu verwenden.
Die neuen String-Bibliotheken können auch mit großen Strings effizient umgehen. Die Länge der Strings ist nahezu unbegrenzt. Aus diesem Grund sind die Bibliotheken auch für das Bearbeiten von großen Textdateien und Web-Inhalten geeignet.
UTF-8 ist eine Kodierung, die den vollständigen Zeichenumfang gemäß UNICODE darstellen kann.
UTF-8 hat im World Wide Web eine weite Verbreitung und wird vom World Wide Web Consortium (W3C) empfohlen.
UTF-8 ist aufgrund der ASCII-Kompatiblität kompatibel zu Altsystemen.
UTF-8 bietet ein hohes Maß an Interoperabilität.
UTF-8 arbeitet speicherplatzoptimierend.
Durch die neuen String-Bibliotheken können Sie einen zuvor definierten String über entsprechende Methoden abfragen, so wie Sie es von anderen Hochsprachen kennen.
Len()udiStringLen := myString.Len(); if udiStringLen = 22 THEN ...
Seit CODESYS 3.5.18.0 können Sie den Compiler so einzustellen, dass der Inhalt von Variablen vom Typ STRING als UTF-8-Kodierung interpretiert wird. Die Option UTF-8-Kodierung für STRING aktivieren Sie in den Projekteinstellungen in der Kategorie Compile-Optionen.
Wenn Sie nicht alle STRING-Variablen eines Projekts als UTF-8 kodiert behandeln wollen, müssen Sie diese Option ausschalten. Danach können Sie einzelne Literale vom Typ STRING von Fall zu Fall mit einer UTF-8-Kodierung versehen.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';Durch die Möglichkeiten der UTF-8-Kodierung müssen Sie in CODESYS nicht den Datentyp WSTRING verwenden, um einen erweiterten Zeichenvorrat zu nutzen. Die für WSTRING zugrunde liegende UCS-2-Kodierung benötigt je nach Anwendung unter Umständen mehr Speicherplatz als eine UTF-8-Kodierung. Die UCS-2-Kodierung verwendet pro Zeichen immer ein WORD und kann nur die Zeichen U+0000 bis U+D800 und U+DFFF bis U+FFFD darstellen. Die UTF-8-Kodierung benötigt zwischen ein und vier Bytes pro Zeichen. Es können damit alle Unicode-Zeichen verarbeitet werden.
Wenn Sie bei UTF-8-Kodierung versuchen, ein bestimmtes Zeichen über einen bestimmten Index zu erreichen, führt dies aufgrund der variablen Länge zu unerwarteten Ergebnissen.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
byValue := sValue[13]; // The 'u' is NOT the 13th character in the string
xOk := byValue <> 16#75;Sie müssen den Index eines Zeichens durch Iteration durch die Zeichenkette bestimmen.
VAR
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
fbsValue : STR.UTF8Literal := (psValue:=ADR(sValue));
fbRange : STR.Range := (itfString:=fbsValue);
diRune : STR.RUNE;
udiIndex, udiLength : UDINT;
xOk : BOOL;
END_VAR
WHILE (diRune := fbRange.GetNextRune(udiLength=>udiLength)) <> 0 DO
IF diRune = 16#75 (* 'u' *) THEN
EXIT;
END_IF
udiIndex := udiIndex + udiLength;
END_WHILE
xOk := sValue[udiIndex] = 16#75 (* 'u' *);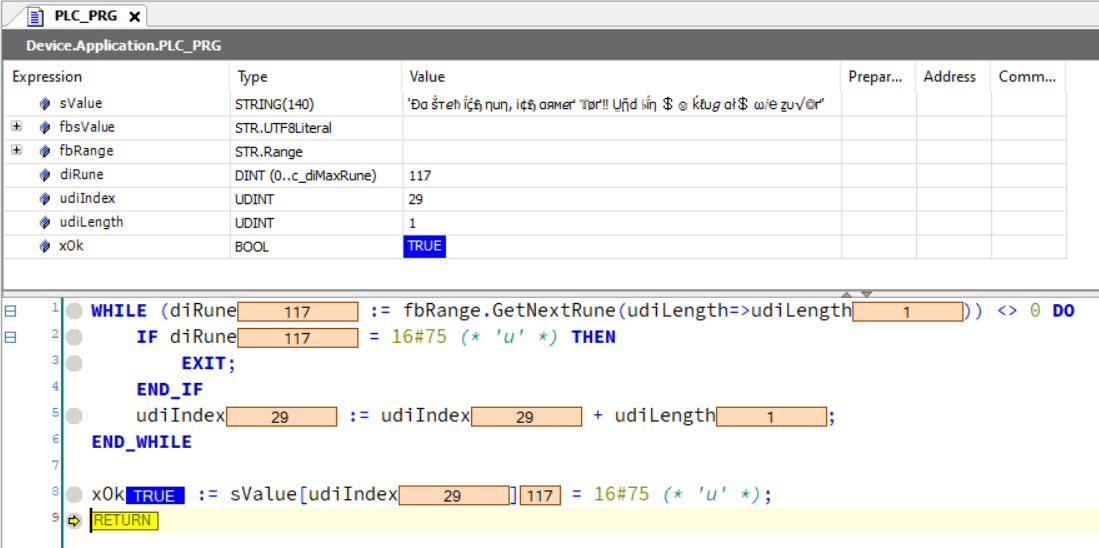
Nachteile der etablierten STRING-Funktionen
In den bisher etablierten STRING-Funktionen aus der Standardbibliothek werden die Parameter vom Typ STRING bei der Übergabe an die Funktionen kopiert. Der Rückgabewert wird mit der Zuweisung ebenfalls an eine Variable kopiert.
VAR
sValue : STRING;
END_VAR
sValue := CONCAT(CONCAT(CONCAT('Da steh ich nun,', ' ich armer Tor!'), ' Und bin so'), ' klug als wie zu vor');
// -> Copy, LEN -> Copy, LEN -> Copy, LEN -> Copy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LENVor der Verarbeitung der Parameter vom Typ STRING in den jeweiligen Funktionen muss oft deren Länge durch Iteration bis zum abschließenden Null-Zeichen ermittelt werden. Bei längeren Zeichenketten verlängern diese Kopier- und Iterationsvorgänge die Bearbeitungszeit der Applikation. Die Länge der Zeichenketten ist für die Anwendung dieser Funktionen auf eine Länge von 255 Zeichen begrenzt.
Verwendung der Schnittstelle IString
Die Schnittstelle STR.IString wurde eingeführt, um die Datenstruktur, die die Informationen über einen String verwaltet, als Referenz weiterreichen zu können. Das ist ein großer Unterschied zu den bisher etablierten STRING-Funktionen, welche die Schnittstelle STR.IString nicht implementieren.
Des Weiteren darf sich die Größe eines Strings (der jeweilige Speicherplatz für die UTF-8-kodierten Zeichen) im Zahlenbereich UDINT (4 ≦ udiSize ≦ 16#FFFF_FF00) befinden.
Verweis auf das jeweilige Speichersegment
Aktuelle Kapazität (→
GetSegment)Länge (→
Len) in ByteAnzahl der Zeichen (→
RuneCount)
STR.IStringVAR
itfString : STR.IString;
udiLength, udiSize, udiRuneCount : UDINT;
pbySegment : POINTER TO BYTE;
xValid : BOOL;
END_VAR
udiLength := itfString.Len(); // Current length in byte
pbySegment := itfString.GetSegment(udiSize=>udiSize); // Address first byte, capacity of the segment in bytes
udiRuneCount := STR.RuneCount(itfString); // Current number of "characters" in the segment
xValid := itfString.IsValid(); // Indication that a valid UTF-8 encoding is present.Zusammenhang: "Zeichen" und "Rune"
Der Begriff "Rune" kommt in den Bibliotheken und im Quellcode vor und bedeutet genau dasselbe wie "Unicode-Codepunkt", mit einem interessanten Zusatz.
Die Bibliotheken definieren das Wort "Rune" als Alias für den Typ DINT. Somit kann der Anwender klar erkennen, wann ein Integerwert einen Codepunkt darstellt. Außerdem wird das, was als Zeichenkonstante vorstellbar ist, als Runenkonstante bezeichnet.
Beispiel: Der Typ und Wert des Ausdrucks WSTRING#"⌘" ist eine Rune mit dem Integerwert DINT#16#2318.